GraphQL에 대해서
GraphQL은 메타(페이스북)에서 제안한 HTTP를 기반으로 하는 프로토콜로, 현재는 23개의 언어에 프레임워크가 오픈소스로 개발되어 있다. 또한 메시지 프로토콜 구조에 대한 스펙이 함께 공개되어있기 때문에 이를 바탕으로 직접 프레임워크를 작성하는 것도 가능하다.
기본 구조
GraphQL은 크게 리소스를 요청하기 위한 Query 구조와 리소스를 제어하기 위한 Mutation 구조 두가지로 구분할 수 있다. 하지만 쿼리 언어 자체에 대한 자세한 설명은 공식 홈페이지에서 볼 수 있기 때문에, 굳이 기본 문법을 나열하기 보다는 단순한 데이터 모델의 Query와 Mutation이 Python3에서 어떻게 표현되는지를 중심으로 간략하게만 적어둔다.
Python3에 대해서
코드는 전부 Python3의 현재 Stable 버전인 3.11 버전에 맞춰 작성할 것이다. 또한 Server framework로 FastAPI와 strawberry를 함께 사용하고, Client library로는 gql을 사용한다.
Server-side
# app.py
from model import Query, Mutation
from fastapi import FastAPI
from strawberry.fastapi import GraphQLRouter
import uvicorn
import strawberry
def init(*argv):
schema = strawberry.Schema(query=Query, mutation=Mutation)
graphql_app = GraphQLRouter(schema)
_app = FastAPI()
_app.include_router(graphql_app, prefix="/graphql")
return _app
app = init()
def runners():
uvicorn.run("api:app", port=5000, reload=True)
if __name__ == "__main__":
runners()
가장 단순하게 서버 어플리케이션을 구현하면 이렇게 쓸 수 있다. 간단하게 보면 FastAPI에서 router를 정의하고, routing path와 연결하는 코드이다. 여기에서 중요한 부분은 init 함수에서 schema를 정의하는 부분인데, Schema 객체를 만들면서 query와 mutation 객체를 파라미터로 전달하고 있음을 알 수 있다. 서버는 이 schema 객체를 통해서 Request의 쿼리를 검증하고 해석한다.
GraphQL은 쿼리 언어이기 때문에 스키마가 작성되어야 하는데, strawberry 라이브러리는 Python3의 객체 구조를 스키마와 동일하게 다룰 수 있도록 도와준다. 이름과 나이 정보를 갖고있는 User 모델을 표현할 때 GraphQL 에서는 이렇게 작성한다.
type User {
name: String!
age: Int
}
여기에서 타입 뒤에 느낌표는 non-nullable을 의미한다. 이 모델이 객체로 표현될 때는 아래와 같은 형태로 작성된다.
# GraphQL 모델
@strawberry.type
class User:
name: str
age: int | None
가장 단순한 모델로 User 객체를 정의한다. GraphQL에서의 데이터 타입 중에서 type을 표현하기 위해 strawberry.type 데코레이터를 사용하고 있음을 볼 수 있다.
그 다음으로 Query와 Mutation을 정의해야 하는데, GraphQL에서의 구조를 보면 이렇다.
type Query {
user(name: String): User
}
type Mutate {
addUser(name: String!, age: Int): User
}
여기에는 User 데이터 타입을 조회하는 Query와 User 데이터 타입을 조작하는 Mutate를 정의해 두었다. 시스템은 이 스키마를 참고로 사용자가 Request에 보내는 쿼리 언어문을 해석하는데, 자세한 내용은 Client-side에서 추가로 설명을 적어둔다. 위의 User 객체와 마찬가지로 Python3에서는 이렇게 표현한다.
# Data model
@strawberry.type
class Query:
@strawberry.field
def user(self, name: str | None = None) -> User | None:
if name is None:
return users[0]
for u in users:
if u.name == name:
return u
else:
return None
# Mutation model
@strawberry.type
class Mutation:
@strawberry.mutation
def add_user(self, name: str, age: int | None) -> User:
user = User(name=name, age=age)
users.append(user)
return user
# Fake database
users: list[User] = []
아래 “Fake database”는 Database에서 Select, Insert를 단순히 흉내내기 위해 만든 List 변수이다. 여기에서 Query 항목에있는 user는 User 객체를 조회하기 위해 어떤 파라미터가 필요한지에 대한 정보이다. 위의 스키마에서 user 라는 이름은 strawberry.field 데코레이터를 갖고있는 user 함수와 같다. 다음에 있는 Mutation은 Mutate타입을 표현하는 객체로, 마찬가지로 addUser가 Mutation.add_user에 대응한다. 파라미터에 non-nullable이 없는 경우에는 기본 타입만, nullable 인 경우에는 None을 타입 힌트에 적어주어야 한다.
strawberry 라이브러리에서 알아두어야 할 것은 GraphQL에서는 타입 시스템에서 Query, Mutation도 객체 모델과 마찬가지로 type으로 표현되기 때문에 strawberry.type 데코레이터를 사용하는데, 이외에 input, enum 타입을 표현할 때는 strawberry.input, strawberry.enum 으로 쓸 수 있다는 것이다.
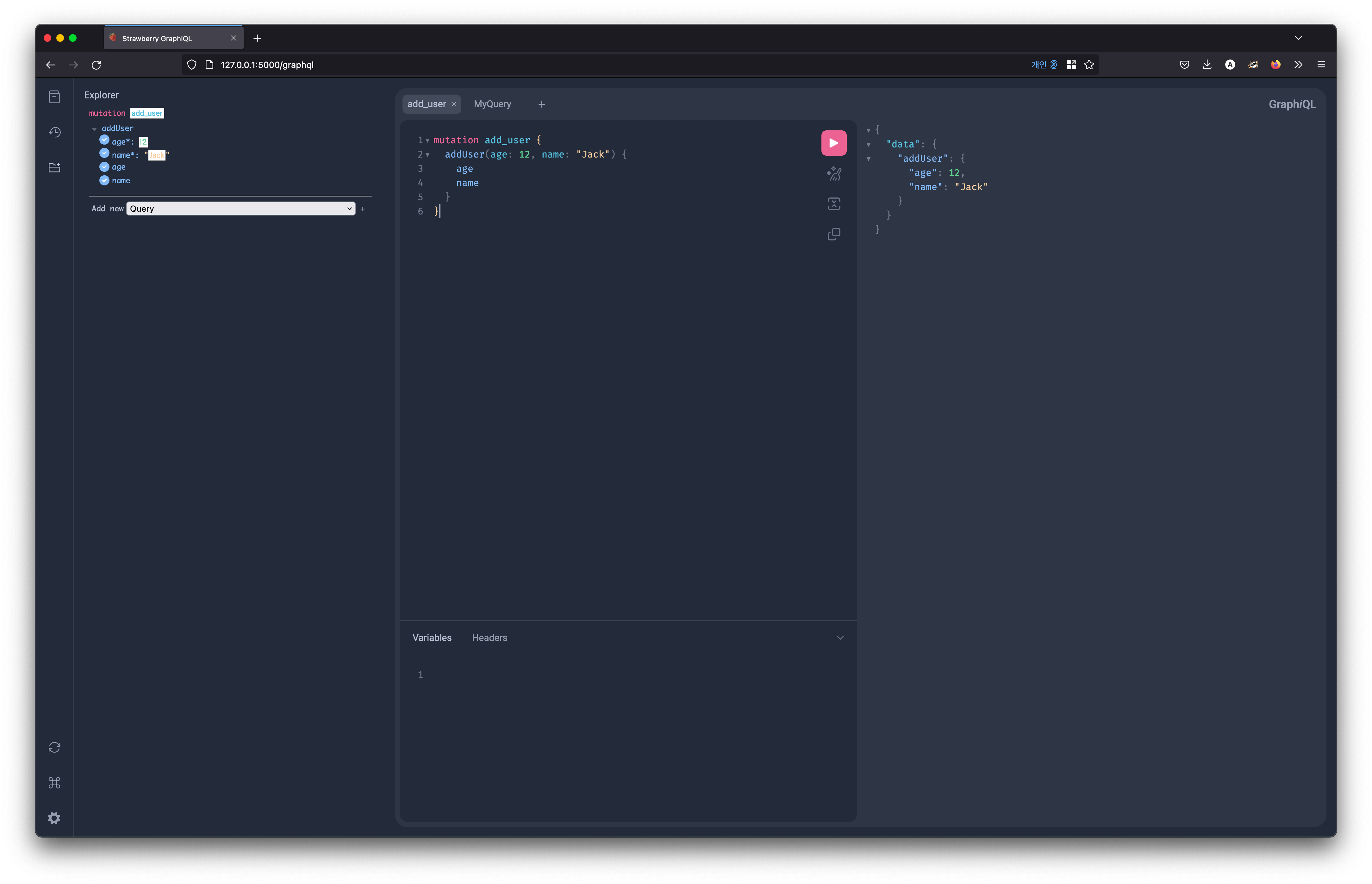
로컬에서 서버를 구동시킨 뒤 router path로 등록한 경로로 웹브라우저를 통해 접근하면 Playground(여기서는 http://127.0.0.1:5000/graphql)에 접속이 가능한데, 아래와 같은 화면에서 객체화된 스키마를 직접 테스트해볼 수 있다.
Client-side
다음은 위의 User 객체모델이 client에서는 어떻게 작성되는지에 대해 적어본다. client에는 server-side에서 정의한 schema가 필요하다. gql은 이 schema 문서를 읽어서 입력되는 쿼리문의 유효성을 검증하고 Request를 보내는 작업을 진행한다. User 객체모델에 대응하는 schema는 아래와 같다.
type User {
name: String!
age: Int
}
type Query {
user(name: String): User
}
type Mutate {
addUser(name: String!, age: Int): User
}
schema {
query: Query
mutation: Mutate
}
server-side에서의 스키마와 완전히 같음을 알 수 있다. 한가지 추가된 것은 가장 마지막에있는 schema인데, 이 schema가 위의 모든 type을 위한 스키마 구문이 된다.
이제 이 스키마 문서를 gql 라이브러리를 이용해서 이러한 형태로 사용할 수 있다.
import os
from graphql import build_ast_schema, parse
from gql import gql, Client
from gql.transport.requests import RequestsHTTPTransport
def main():
sample_path = os.path.join(os.path.dirname(__file__), "schema", "sample.graphql")
doc = ""
with open(sample_path) as fd:
doc = parse(fd.read())
sample = build_ast_schema(doc)
client = Client(
schema=sample,
transport=RequestsHTTPTransport(
url='http://127.0.0.1:5000/graphql', # server address
)
)
위 코드에서 client 객체에 호스트 서버의 URL 주소와 스키마 문서를 객체화 해서 파라미터로 전달해준다. 그리고 이제 실제로 실행할 쿼리문을 아래와같이 작성한다.
query = gql(
"""
query user($name: String){
user(name: $name) {
name
age
}
}
"""
)
mutate = gql(
"""
mutation add_user($name: String!, $age: Int!) {
addUser(name: $name, age: $age) {
age
name
}
}
"""
)
여기에서 query는 데이터 쿼리를 위한 구문으로, 스키마에서의 user 타입에서 name을 변수화해서 파라미터로 전달받고, 그 결과로 name과 age 값을 반환하도록 요청하는 것을 의미한다. 여기에서 외부에서 입력할 변수와 내부의 파라미터의 맵핑이 user(name: $name)에서 이뤄지고 이 변수에 대한 데이터 타입을 query user($name: String)에서 정의하고있다.
그 다음에있는 mutate는 데이터를 추가하는 구문인데, 스키마 문서에 정의해둔대로 호출 쿼리문을 작성하고, 위의 query와 마찬가지로 가장 바깥에있는 addData에서 name과 age 변수의 타입을 정의하고 그 안에있는 addUser에서 스키마 문서에 미리 정의해둔 addUser의 name, age와 대응하는 파라미터 이름이 무엇인지 서로 맵핑하도록 하는 쿼리이다.
이제 아래에는 위의 gql로 객체화한 쿼리문이 client를 통해 어떻게 실행되는지에 대한 코드이다.
# res = client.execute(mutate, variable_values=dict(name="Bill", age=35))
res = client.execute(query, variable_values=dict(name="Dick"))
print(res)
주석 처리되어있는 라인은 mutate 쿼리를 실행할 때의 구문이고, 아래에있는 라인은 query 쿼리를 실행할 때의 구문이다. 변수를 통해 쿼리를 수행하기 위해 variable_values 파라미터에 dict 타입으로 파라미터 값들을 전달하고 있다.
마무리
메시지 프로토콜인만큼 프로그램을 작성하려는 언어와는 별개로 쿼리 구문의 문법을 익혀야 한다. 또한 client-side에서 예시에 사용한 gql 라이브러리의 경우에는 객체모델과 쿼리를 맵핑하는 기능이 아직 없기 때문에 server와 client를 전부 python3으로 구현하려 한다면 이에 대한 부분을 해결해야 할 필요가 있다.
하지만 GraphQL 재단에서는 Rest API과 비교했을 때의 장점이 계층화된 데이터를 요청해야 할 때 RestAPI는 각 계층의 데이터를 따로 요청해야 하지만, GraphQL은 한번에 묶어서 요청을 할 수 있다는 점이라고 소개하고있다. SQL을 완전히 대체할 수는 없겠지만 이러한 점은 용도에 따라 장점으로 생각해도 충분할 것 같다.